Open Refine
Open Refine (som tidigare hette Google Refine) är att gratisverktyg för att tvätta och bearbeta data. Med Open Refine kan du bland annat:
- Identifiera och harmonisera stavningsvariationer (till exempel "Ericsson Ab", "Ericsson", "Ericson" => "Ericsson")
- Använda externa API:er för att komplettera ditt dataset. Till exempel genom att anropa en geokodare som gör om adresser till longituder och latituder.
- Köra reguljära uttryck.
- Jobba med stora mängder data.
Open Refine är framför allt användbart när man jobbar med textdata. Om du har numerisk data och vill göra beräkningar är det vanligen enklare att använda Excel eller något annat kalkylprogram.
Varje databearbetning i Refine består av två steg: 1) Välj vilken dela av datan du vill jobba med genom att applicera ett facet (filter). 2) Applicera en funktion (ofta genom att klicka på en kolumnrubrik och välj Edit column).
Importera data
Öppna Open Refine, välj Create Project > Web Addresses (URLs) och klistra in följande url: http://jensfinnas.github.io/refine-regex-tutorial/data/anfo%CC%88randen_2013-2014.xml.
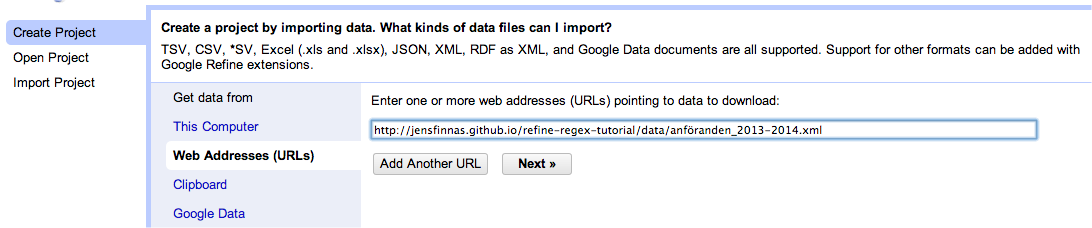 Källa: http://data.riksdagen.se/Data/Anforanden/
Källa: http://data.riksdagen.se/Data/Anforanden/
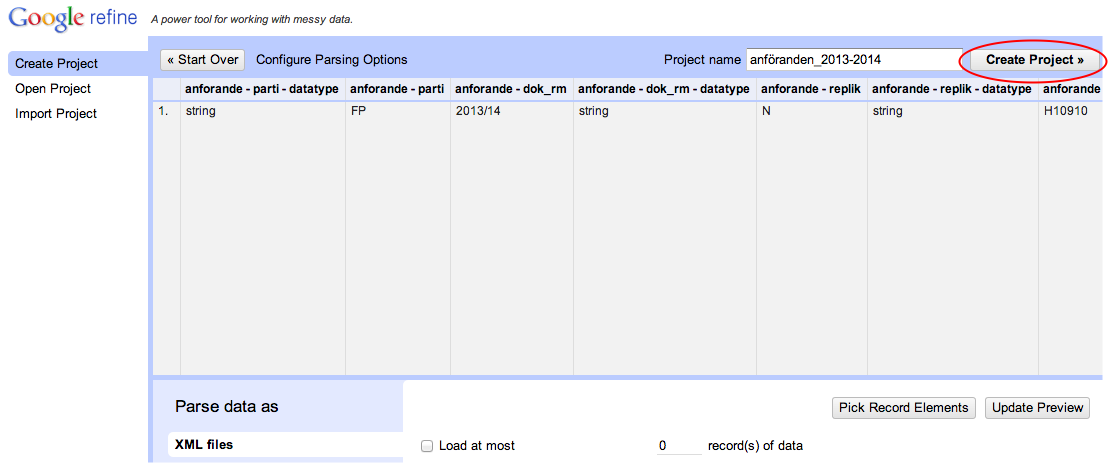
Exportera till Excel
Välj Export > Excel. Öppna den fil som laddas ner.
Skapa en ny kolumn till höger om kolumnen anforande - anforandetext. För att söka i texten använd formeln =FIND("sökord", CELLREFERENS).

Den här koden returnerar ett felmeddelande om den inte hittar nån match. Annars en siffra (som anger på vilken plats ordet förekommer). Kopiera formeln neråt genom hela datasetet.
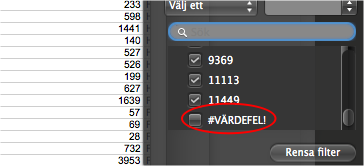
Välj Data > Filter och filtrera bort alla värdefel.
Formatera datum korrekt
Klicka på kolumnen anforande - dok_datum och välj sedan Edit column > Add column based on this column.
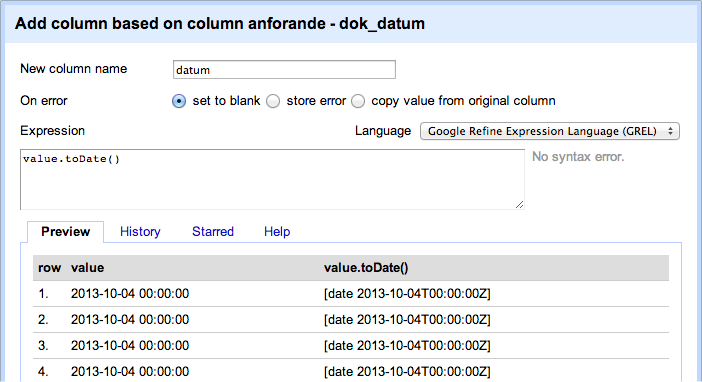
Applicera följande kod: value.toDate().
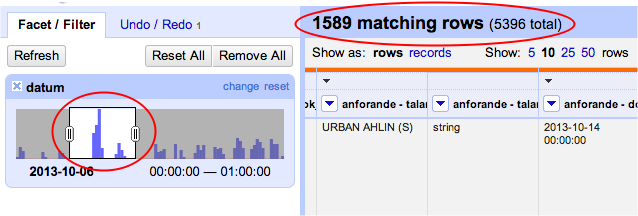
Vi kan nu filtrera på datum. Klicka på den nya kolumnen Datum (eller vad du valde att kalla den) och välj Facet > Timeline facet.
Filtrera på ett parti eller annan kategori
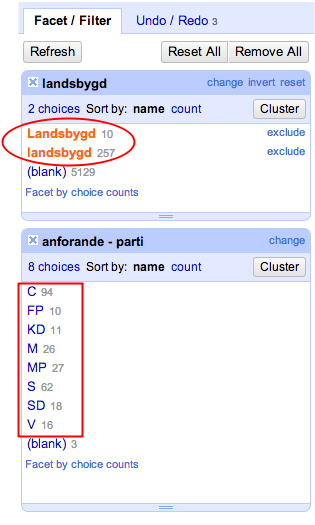
Klicka på anforande - parti och välj Facet > Text facet.
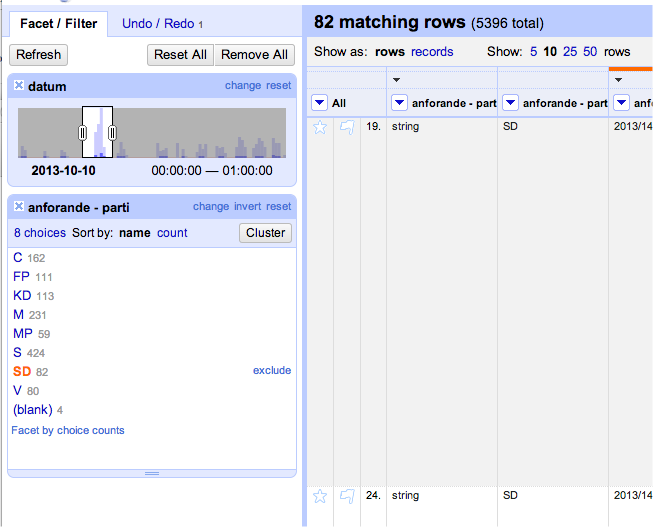
Vi kan nu välja att endast visa anföranden från ett visst parti från en viss tid.
Reguljära uttryck
Reguljära uttryck (regular expression, regex, regexp) är en syntax för att göra avancerade mönstersökningar i textsträngar. Vi kan till exempel söka efter alla personnummer, webbadresser, akademiska titlar och så vidare. Reguljära uttyck går att tillämpa i de flesta programmeringsspråk.
Steg 1: Definiera tecknet
^ |
Början av en sträng |
$ |
Slutet av en sträng |
. |
Vilket tecken som helst |
[ ] |
Matchar något av tecknen inom klammern. Till exempel [aoueiyåäö] matchar en vokal, [a-ö] en liten bokstav mellan a och ö och E-H en stor bokstav mellan E och H. |
\s |
Mellanslag |
\S |
Icke-mellanslag |
\d |
Siffra |
\D |
Icke-siffra |
Definiera antal tecken
* |
Hur många tecken som helst av föregående. |
{3} |
Matchar exakt tre tecken. |
{3,5} |
Matchar exakt tre-fem tecken. |
{3,} |
Matchar tre tecken eller fler. |
Komplett lista över funktioner: http://www.tutorialspoint.com/python/python_reg_expressions.htm
Exempel
Exempeltext:
Carl Bildt, 64, (M), Fredrik Reinfeldt, 48, (M) och Annie Lööf, 30, (C) möttes i Rosenbad den 12.3.2014.
– Jag är mycket nöjd över våra samtal, säger Bildt.
| Sök årtal |
\d{4} eller \d\d\d\d
|
Carl Bildt, 64, (M), Fredrik Reinfeldt, 48, (M) och Annie Lööf, 30, (C) möttes i Rosenbad den 12.3.2014. |
| Sök ålder | , (\d{1,2}), |
Carl Bildt, 64, (M), Fredrik Reinfeldt, 48, (M) och Annie Lööf, 30, (C) möttes i Rosenbad den 12.3.2014. |
| Sök citat | –.*$ |
Carl Bildt, 64, (M), Fredrik Reinfeldt, 48, (M) och Annie Lööf, 30, (C) möttes i Rosenbad den 12.3.2014.
– Jag är mycket nöjd över våra samtal, säger Bildt.
|
| Sök partiförkortningar | \([A-Ö]{1,2}\) |
Carl Bildt, 64, (M), Fredrik Reinfeldt, 48, (M) och Annie Lööf, 30, (C) möttes i Rosenbad den 12.3.2014.
|
Övning:
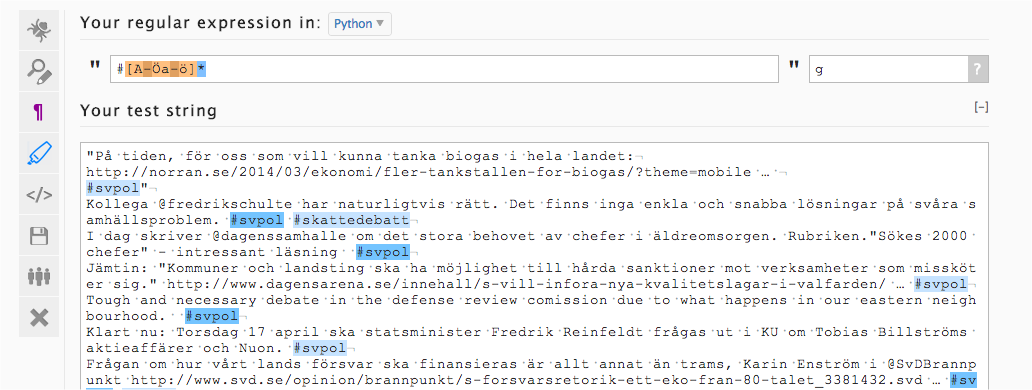 Gå till http://regex101.com/#python
Gå till http://regex101.com/#python
Klistra in texten från http://jensfinnas.github.io/refine-regex-tutorial/data/tweets.txt
- Hitta alla siffror
- Hitta alla Twitter-namn (@jensfinnas)
- Hitta alla hashtaggar (#XXXXX).
- Hitta alla url:ar (http://).
Reguljära uttryck
Se till att du inte har några aktiva facets. Klicka på anforande - anforandetext och välj Edit column > Add column based on this column. Applicera följande kod. Välj Jython som språk den här gången.
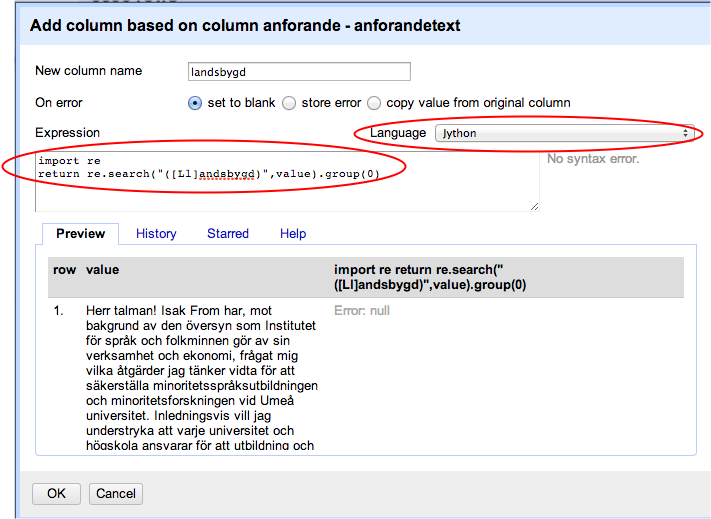
import re
return re.search("([Ll]andsbygd)",value).group(0)
Vi har nu skapat en ny kolumn som innehåller ordet "landsbygd" eller "Landsbygd" om det ingick i anförandet. Vi kan nu applicera ett text facet på den här kolumnen och på partikolumnen för att se vilka partier som använder det här ordet mest.
Här är ett exempel på ett lite mera avancerat reguljärt uttryck.
import re
return re.search("^(\S{3,4}) talman",value).group(1)
Här söker vi efter
-
^början på en rad -
\S{3,4}tre eller fyra tecken som inte är mellanslag. -
talmanföljt av mellanslag talman. -
()anger att det är bara ordet inom parentesen som vi vill fånga in.